
OpenRefine est un logiciel qui permet d’importer des données et de les manipuler un peu comme dans Excel mais avec pas mal de fonctions supplémentaires. On trouve peu de documentation en français sur le sujet, alors je vais vous aider à y voir un peu plus clair. Cet outil trouvera surement sa place dans votre trousse à outils d’SEO.
OpenRefine originellement nommé Google Refine se trouve sur ce site: http://openrefine.org/
Importation des données:
Lors de la phase d’import, vous pouvez indiquer le format de votre fichier (csv, tsv, url web, xml, json…) , le séparateur, savoir si il y a des entêtes, le nombre de lignes à ne pas importer…
Et pour les SEO qui veulent importer du log Apache, voila comment on s’y prend. Importez votre fichier en mode Line-based text files afin que tout arrive dans une seule colonne. Renommez tout d’abord la colonne Column 1 en Column. Puis dans l’onglet Undo/redo, cliquez apply et importez ce code.
[
{
"op": "core/column-split",
"description": "Split column Column by separator",
"engineConfig": {
"facets": [],
"includeDependent": false
},
"columnName": "Column",
"guessCellType": true,
"removeOriginalColumn": true,
"mode": "separator",
"separator": "-",
"regex": false,
"maxColumns": 3
},
{
"op": "core/column-addition",
"description": "Create column Time at index 3 based on column Column 3 using expression grel:value[2,value.indexOf(\"]\")].toDate(\"dd/MMM/yyyy:hh:mm:ss\")",
"engineConfig": {
"facets": [],
"includeDependent": false
},
"newColumnName": "Time",
"columnInsertIndex": 3,
"baseColumnName": "Column 3",
"expression": "grel:value[2,value.indexOf(\"]\")].toDate(\"dd/MMM/yyyy:hh:mm:ss\")",
"onError": "set-to-blank"
},
{
"op": "core/column-addition",
"description": "Create column Method at index 3 based on column Column 3 using expression grel:value.substring(value.indexOf('\"') + 1).partition('\"')[0].split(\" \")[0]",
"engineConfig": {
"facets": [],
"includeDependent": false
},
"newColumnName": "Method",
"columnInsertIndex": 3,
"baseColumnName": "Column 3",
"expression": "grel:value.substring(value.indexOf('\"') + 1).partition('\"')[0].split(\" \")[0]",
"onError": "set-to-blank"
},
{
"op": "core/column-addition",
"description": "Create column Path at index 3 based on column Column 3 using expression grel:value.substring(value.indexOf('\"') + 1).partition('\"')[0].split(\" \")[1]",
"engineConfig": {
"facets": [],
"includeDependent": false
},
"newColumnName": "Path",
"columnInsertIndex": 3,
"baseColumnName": "Column 3",
"expression": "grel:value.substring(value.indexOf('\"') + 1).partition('\"')[0].split(\" \")[1]",
"onError": "set-to-blank"
},
{
"op": "core/column-addition",
"description": "Create column Agent at index 3 based on column Column 3 using expression grel:value.rpartition('\"')[0].rpartition('\"')[2]",
"engineConfig": {
"facets": [],
"includeDependent": false
},
"newColumnName": "Agent",
"columnInsertIndex": 3,
"baseColumnName": "Column 3",
"expression": "grel:value.rpartition('\"')[0].rpartition('\"')[2]",
"onError": "set-to-blank"
},
{
"op": "core/column-addition",
"description": "Create column ResponseCode at index 3 based on column Column 3 using expression grel:with(value.partition('\" ')[2], s, s.partition(\" \")[0])",
"engineConfig": {
"facets": [],
"includeDependent": false
},
"newColumnName": "ResponseCode",
"columnInsertIndex": 3,
"baseColumnName": "Column 3",
"expression": "grel:with(value.partition('\" ')[2], s, s.partition(\" \")[0])",
"onError": "set-to-blank"
},
{
"op": "core/column-addition",
"description": "Create column ContentLength at index 3 based on column Column 3 using expression grel:with(value.partition('\" ')[2].partition(\" \")[2], s, s.partition(\" \")[0])",
"engineConfig": {
"facets": [],
"includeDependent": false
},
"newColumnName": "ContentLength",
"columnInsertIndex": 3,
"baseColumnName": "Column 3",
"expression": "grel:with(value.partition('\" ')[2].partition(\" \")[2], s, s.partition(\" \")[0])",
"onError": "set-to-blank"
},
{
"op": "core/column-addition",
"description": "Create column Referer at index 3 based on column Column 3 using expression grel:with(value.partition('\" ')[2].partition(\" \")[2], s, s.partition(' \"')[2].partition('\" ')[0])",
"engineConfig": {
"facets": [],
"includeDependent": false
},
"newColumnName": "Referer",
"columnInsertIndex": 3,
"baseColumnName": "Column 3",
"expression": "grel:with(value.partition('\" ')[2].partition(\" \")[2], s, s.partition(' \"')[2].partition('\" ')[0])",
"onError": "set-to-blank"
},
{
"op": "core/column-removal",
"description": "Remove column Column 3",
"columnName": "Column 3"
}
]
Manipuler vos données:
Normalement, une fois votre import terminé, vous voyez un tableau de données. Lorsque vous cliquez sur une colonne, vous pouvez définir des facets. Ces facets vous permettront de filtrer vos données par texte, nombre, et même expression régulière. Votre tableau se filtrera instantanément sur la valeur choisie, et vous aurez sur la droite la liste de ces valeurs ainsi que le nombre de lignes qu’elles possèdent.
Par exemple, si je met le code suivant dans ma colonne Referrer en tant que Custom Text Facet (cela permet de ne conserver que le domaine).
if(value == "-", value, value.partition("://")[2].partition("/")[0])
J’obtiens ceci:
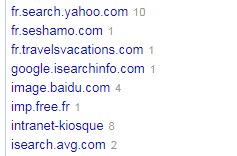
Après, on peut facilement filtrer ses données par valeur pour les corriger. Si vous avez des datas qui commencent / se terminent par du blanc, alors faites Edit Cells > Common Transforms >Trim Leading. Il y a même un algo qui vous permet de retrouver des catégories qui ne seraient pas écrites exactement pareil via des calculs heuristiques.
Dans Edit Column, vous avez également la méthode split qui vous permet de scinder une information en 2. Et là, on peut même le faire depuis un champ en Json.
Importer des services Web:
L’outil peut requêter des API externes. On peut ainsi imaginer d’aller chercher des latitudes / longitudes à partir d’une adresse via OpenStreetMap, les réalisateur à partir de titres de film via Freebase, ou même la langue du contenu à partir de Google Translate. De nombreuses API sont d’ores et déjà disponibles.
Conclusion:
L’outil est extrêmement rapide et ne plantera pas comme Excel peut malheureusement le faire avec des fichiers volumineux. On peut même étendre ses possibilitées via l’ajout de plugins. Il y ad’ailleurs l’excellent plugin VIB qui vous permettra de rajouter la fonctionnalité de RECHERCHEV d’Excel (jointure entre plusieurs tables). Si cet article vous a intéressé, alors je ne peux que vous conseillez de suivre les vidéos d’introduction disponibles sur leur site.
Et si vous avez une expérience à partager, alors les commentaires sont là pour ça 🙂



")
