
Aujourd’hui, j’ai eu la chance de participer à un événement gratuit proposé par SFEIR pour évangéliser les personnes à la GCP. Cela m’a permis de comprendre l’évolution du Cloud Google depuis ses débuts (il y a vraiment beaucoup d’icônes désormais) et de mieux appréhender les solutions et leurs contraintes. Google propose ainsi de mettre à disposition son architecture (celle qui permet de faire tenir la charge de gmail, youtube, play store…) à tous et pour un coût assez faible.
Voyons ensemble un petit récapitulatif de tout ça.
Gérer son infrastructure:
Plusieurs applicatifs sont à notre disposition pour répondre à tous les niveaux d’intégration du Cloud dans votre infrastructure. Nous avons ainsi:
– Compute Engine,
– App Engine,
– Kubernates.
Compute Engine vous permettra de lancer des machines virtuelles scalables (choisissez le nombre de CPU, la RAM, la taille de disque…). Au passage, pensez à cocher préemptable pour baisser les coûts (sachez quand même que vos machines préemptés pourront être réalloués à d’autres si les besoins s’en font ressentir). A noter que la facturation se fait à la seconde.
App Engine vous permettra de lancer des applications et de pouvoir absorber facilement des pics de charge. Ici, vous pouvez démarrer une application et la rendre opérationnelle en quelques millisecondes.
Kubernates Engine vous permet de gérer vos containers. Containers qui sont ajustables en fonction du trafic – vous pouvez définir un nombre de pods (d’instances) minimum et maximum. Vous pouvez même rediriger une partie du trafic d’une version de votre application à une autre version via des tests AB très simplement. Cela vous permet ainsi de ne plus avoir de downtime lors dès migration par exemple.
Le stockage de fichiers:
Lorsque vous écrivez une application pour le cloud, il n’y a plus de systèmes de fichiers
(sauf pour Compute Engine), et donc vos fichiers ressources doivent être placés dans le Cloud Storage (équivalent d’amazon S3). Vous pouvez alors y définir des buckets (espaces de stockage) quasi illimité qui seront accessible en HFS.
Une astuce pour gagner du temps de dév est de passer des paramètres de références (comme une liste de valeur) d’une application via Google Spreadsheet. Cela nous évite alors de recoder une interface, car Spreadsheet est nativement géré.
Le stockage de données:
Plusieurs systèmes de bases se challengent pour répondre à toutes les problématiques. Elles peuvent recevoir toutes des millions de lignes, mais semblent difficile à appréhender pour les non initiés. Vous avez les anciens services (mySQL, PostGres) qu’on ne présentent plus et les nouveaux.
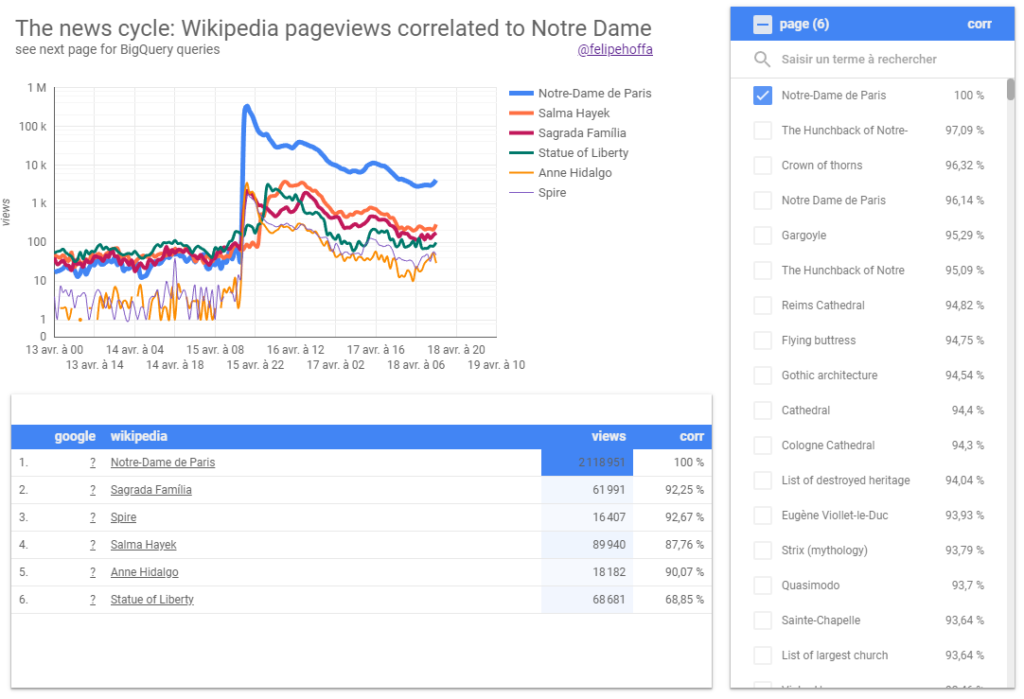
Big Query permet de profiter d’un système de requêtage ultra performant (100 000 insertions par seconde) – idéal pour faire des cubes OLAP. On voit par exemple sur ce graphique quelles sont les corrélations des mots clés interrogés sur Wikipedia lors de l’incendie de notre dame (5 milliards de lignes interrogées en seulement 30 secondes).
Big Table est différent de Big Query et ressemble plus à une sorte de Hbase (où l’on ne peut requêter que via un système d’identifiants mais encore plus rapidement). Il faut donc penser en amont comment sera construite la clé du document afin de pouvoir les filtrer (une requête se base uniquement sur une clé).
Exemple d’identifiant pour filtrer des mails: id_user_date_debut_date_fin_from
Le datastore est une architecture type MongoDB (stockage de documents Json).
Spanner: un système permettant de gérer l’acidité des transactions simultanément sur plusieurs Data Centers ! Cela permet de ne jamais avoir de coupure pour maintenance.
En voici d’autres…
Pub/sub: il s’agit d’un système d’envoi de message (push/pull) type Rabbit MQ.
Dataflow: système qui permet de faire des traitements depuis un stream de données.
Dataproc: combinaison de Apache Hadoop, Spark, Pig et Hive très proche de Dataflow.
Datalab: une architecture type MongoDB pour les Data Scientists.
Cloud DNS: pour créer des sous domaines via des appels API.
Cloud Interconnect: pour paramétrer son réseau de machines.
Cloud Endpoint: sécurisation dans la gestion des api.
StackDriver: gestion des logs.
Cloud functions: créer une fonction (un peu comme des triggers dans des bases de données) qui se déclenchent lors d’événements.
Cloud Machine Learning Engine : transcription de la voix en texte(Speech API) et inversement (Natural Language), analyse d’images (même de vidéo) et reconnaissance d’objets avec Visual API.
Marketplace: lancer des wordpress ou autres applications directement sur le Cloud.
Conclusion:
Un livre blanc qui détaille un peu mieux ma synthèse, est disponible ici:
https://www.sfeir.com/livre-blanc/comprendre-google-cloud-platform/ . Les formations proposées par SFEIR sont éligibles au CPF, et je crois que je vais me laisser tenter. Et pour les autres qui veulent tester depuis chez eux le Google Cloud Platform, sans se ruiner, essayez Qwiklabs, cela vous permettra d’essayer en limitant vraiment votre budget. Vous avez également les tutoriels de Coursera pour vous aider à vous y mettre. Ca, plus la roadmap des développeurs 2019, ca commence à faire beaucoup… 🙂




")
1 réflexion au sujet de « Récapitulatif de la Google Cloud Platform »