
Il y a peu je devais scraper des données provenant de pages dont l’url était du type www.toto.com/page/1.
En cherchant sur les plugins de scrap, je suis tombé sur 2 très intéressant:
Le 1er est plutôt bien pensé, mais nécessite de créer un compte et est limité à 500 pages de scraps. Le 2e lui est moins bien réalisé et ne fait pas de pagination, mais il est open source.
Ni une, ni deux, je me suis lancé dans le dév du 2e plugin, et je vous ai sortie une version alternative avec pagination.
L’extension n’est plus maintenue par son développeur, son site ne répond plus, et il n’a pas répondu à mes sollicitations sur son github.
Du coup, si vous souhaitez installer un plugin de scrap avec pagination, je vous invite à prendre le mien:
https://chrome.google.com/webstore/detail/dbmjjlbalcbgmlniekckllnaiejomiop/publish-delayed?hl=fr
Pour la lancer, faites un clic droit sur une page, puis scrap similar. Ajouter un xpath.
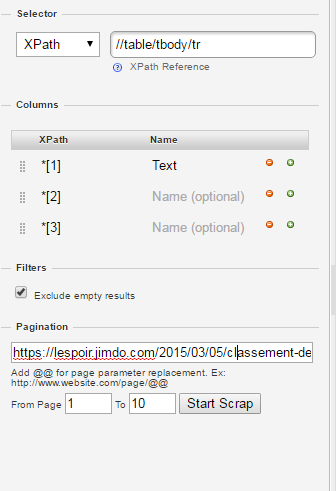
Voici un exemple de configuration.
Pour une table, ajouter ca:
//table/tbody/tr en Xpath, et *[1] , *[2] … dans les champs colums.
Ensuite si il y a une question de pagination, remplacer simplement le numéro de la page dans l’url par @@, indiquer les bornes de pages à scraper, puis cliquez sur Start Scrap.
Pour finir, voici l’adresse du Github: https://github.com/ynizon/scraper





